%%HTML
<script src="require.js"></script>
from IPython.display import display, HTML, clear_output
HTML('''
<script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/2.0.3/jquery.min.js "></script><script>
code_show=true;
function code_toggle() {
if (code_show){
$('div.jp-CodeCell > div.jp-Cell-inputWrapper').hide();
} else {
$('div.jp-CodeCell > div.jp-Cell-inputWrapper').show();
}
code_show = !code_show
}
$( document ).ready(code_toggle);</script><form action="javascript:code_toggle()"><input type="submit" value="Click here to toggle on/off the raw code."></form>
''')

Problem
Sentiment Analysis, often referred to as Opinion Mining, stands as a pertinent and impactful application within the realms of Machine Learning and Natural Language Processing. Its utility spans across a diverse array of applications, encompassing employee feedback assessments, e-commerce customer reviews analysis, and market research endeavors.
Building on our foundational understanding of classification models in Machine Learning 1, today we embark on an exploration of the nuanced methodologies employed for sentiment classification. We will delve into both traditional machine learning approaches and the utilization of TextBlob, a dedicated Natural Language Processing (NLP) library. Throughout this exploration, we will evaluate the merits and drawbacks of each technique, providing a comprehensive understanding of their respective strengths and limitations.
Highlights
- To compare, data was preprocessed similarly, and Naive Bayes used for both TextBlob and Traditional ML.
- Both models surpass the Proportion Chance Criterion (0.41), showcasing high accuracy.
- Traditional ML (0.69 accuracy) slightly outperforms TextBlob (0.66 accuracy) and provides more descriptive features (words).
- TextBlob simplifies text classification with ease and quick implementation.
- Custom models offer greater flexibility, control, and visibility for text classification.
Libraries and Functions
Import Library
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import time
import spacy
import warnings
from warnings import simplefilter
from textblob import TextBlob
from textblob.classifiers import NaiveBayesClassifier
from imblearn.over_sampling import RandomOverSampler
from imblearn.under_sampling import RandomUnderSampler
from sklearn.exceptions import ConvergenceWarning
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import TruncatedSVD
from sklearn.datasets import make_classification
from sklearn.pipeline import Pipeline
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.svm import LinearSVC, SVC
from sklearn.linear_model import SGDClassifier
from sklearn.neighbors import KNeighborsRegressor, KNeighborsClassifier
from sklearn.linear_model import Lasso, Ridge, LogisticRegression
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor, RandomForestClassifier, GradientBoostingClassifier
from sklearn import metrics
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", category=RuntimeWarning)
warnings.filterwarnings("ignore", category=ConvergenceWarning)
Functions
The following functions were defined:
- compute_pcc for computing the Proportion Chance Criterion (PCC) and 1.25 * PCC from a dataframe
- determine_sentiment for getting the Sentiment (3 for positive, 2 for neutral, 1 for negative) from the Rating and Recommended IND columns.
- lemmatize text for turning text into their base form.
def compute_pcc(df):
"""
Compute the Proportion Chance Criterion (PCC) and 1.25 * PCC based on
grouped sentiment counts.
Parameters
----------
df : pandas.DataFrame
DataFrame containing a 'Sentiment' column with categorical labels.
Returns
-------
None
The function prints the Proportion Chance Criterion (PCC) and 1.25*PCC.
"""
grouped_sentiment = df.groupby('Sentiment').size()
num = (grouped_sentiment/grouped_sentiment.sum())**2
ppc = 100*num.sum()
ppc_125 = ppc * 1.25
print(f'Proportion Chance Criterion: {ppc:.2f}')
print(f'1.25 * Proportion Chance Criterion: {ppc_125:.2f}')
def determine_sentiment(row):
"""
Determine sentiment based on rating and recommendation.
Parameters
----------
row : pandas.Series
A pandas Series representing a row of a DataFrame with 'Rating' and 'Recommended IND' columns.
Returns
-------
int
An integer representing the sentiment:
- 3 for positive sentiment (Rating > 3 and Recommended IND == 1)
- 1 for negative sentiment (Rating < 3 and Recommended IND == 0)
- 2 for neutral sentiment (otherwise)
"""
if row['Rating'] > 3 and row['Recommended IND'] == 1:
return 3
elif row['Rating'] < 3 and row['Recommended IND'] == 0:
return 1
else:
return 2
nlp = spacy.load("en_core_web_sm")
def lemmatize_text(text):
"""
Lemmatize the input text using spaCy.
Parameters
----------
text : str
The input text to be lemmatized.
Returns
-------
str
The lemmatized text.
"""
return ' '.join([token.lemma_ for token in nlp(text)])
Dataset
Data Source and Description
This data from Kaggle centers around customer feedback for a Women's Clothing E-Commerce company. References to the company in the review text and body have been replaced with the term "retailer" for privacy and anonymity.
The data holds 23,486 reviews with 10 original features. Each row corresponds to a customer review and features include:
Clothing ID: Integer Categorical variable that refers to the specific piece being reviewed.Age: Positive Integer variable of the reviewers age.Title: String variable for the title of the review.Review Text: String variable for the review body.Rating: Positive Ordinal Integer variable for the product score granted by the customer from 1 Worst, to 5 Best.Recommended IND: Binary variable stating where the customer recommends the product where 1 is recommended, 0 is not recommended.
Positive Feedback Count: Positive Integer documenting the number of other customers who found this review positive.Division Name: Categorical name of the product high level division.Department Name: Categorical name of the product department name.Class Name: Categorical name of the product class name.
A look into the original data gives us:
raw_df = pd.read_csv('Womens Clothing E-Commerce Reviews.csv')
raw_df.drop(raw_df.columns[0], axis=1, inplace = True)
raw_df.head(3)
| Clothing ID | Age | Title | Review Text | Rating | Recommended IND | Positive Feedback Count | Division Name | Department Name | Class Name | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 767 | 33 | NaN | Absolutely wonderful - silky and sexy and comf... | 4 | 1 | 0 | Initmates | Intimate | Intimates |
| 1 | 1080 | 34 | NaN | Love this dress! it's sooo pretty. i happene... | 5 | 1 | 4 | General | Dresses | Dresses |
| 2 | 1077 | 60 | Some major design flaws | I had such high hopes for this dress and reall... | 3 | 0 | 0 | General | Dresses | Dresses |
Methodology and Implementation
In this study, we will use both traditional machine learning methods and TextBlob to classify customer reviews. To gain an apples-to-apples comparison of the results of the classification of using traditional method and that of TextBlob, we use similar preprocessing methods for both instances. Here is a summary of the methodology:
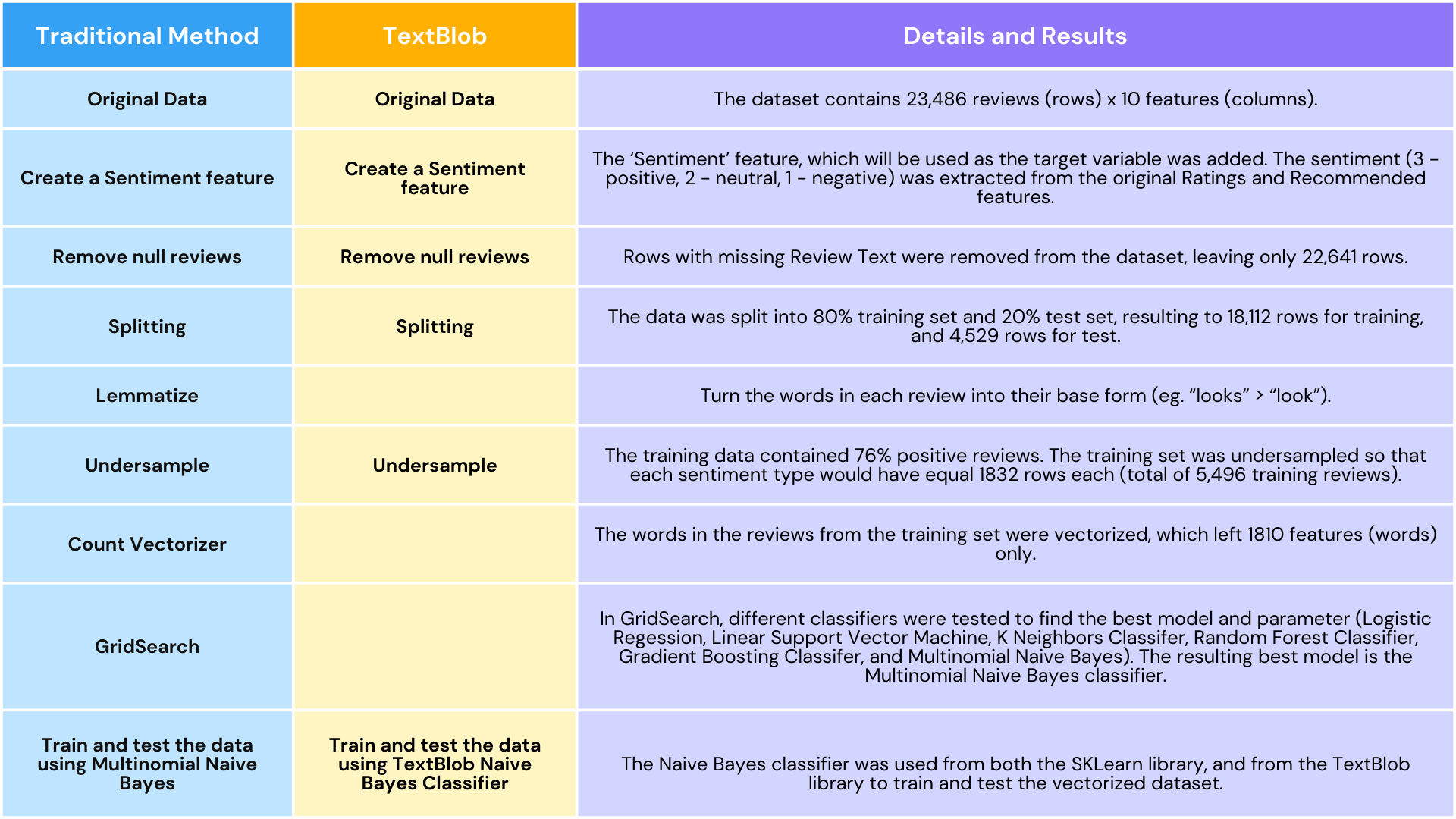
Add a new feature `Sentiment`
A new categorical feature "Sentiment" was added. This will be used as the target variable. Reviews with a rating of 4 to 5 and is recommended by the customer will be Positive reviews (encoded as 3). Reviews with a rating of 1 to 2 and is NOT recommended by the customer will be Negative reviews (encoded as 1). All other reviews will be Neutral (encoded as 2).
raw_df['Sentiment'] = raw_df.apply(determine_sentiment, axis=1)
raw_df.head(3)
| Clothing ID | Age | Title | Review Text | Rating | Recommended IND | Positive Feedback Count | Division Name | Department Name | Class Name | Sentiment | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 767 | 33 | NaN | Absolutely wonderful - silky and sexy and comf... | 4 | 1 | 0 | Initmates | Intimate | Intimates | 3 |
| 1 | 1080 | 34 | NaN | Love this dress! it's sooo pretty. i happene... | 5 | 1 | 4 | General | Dresses | Dresses | 3 |
| 2 | 1077 | 60 | Some major design flaws | I had such high hopes for this dress and reall... | 3 | 0 | 0 | General | Dresses | Dresses | 2 |
Remove null reviews
For this study, the predictor variable that will be used is the Review Text feature, therefore, all rows with null Review Text will be removed.
raw_df.isnull().sum()
Clothing ID 0 Age 0 Title 3810 Review Text 845 Rating 0 Recommended IND 0 Positive Feedback Count 0 Division Name 14 Department Name 14 Class Name 14 Sentiment 0 dtype: int64
raw_df = raw_df.dropna(subset=['Review Text'])
raw_df.isnull().sum()
Clothing ID 0 Age 0 Title 2966 Review Text 0 Rating 0 Recommended IND 0 Positive Feedback Count 0 Division Name 13 Department Name 13 Class Name 13 Sentiment 0 dtype: int64
Data Exploration
The data was explored to see the any trends from the reviews dataset.
df_onlynum = raw_df[['Age', 'Rating', 'Recommended IND', 'Positive Feedback Count', 'Sentiment']]
sentiment_colors = {3:'orange', 1:'black', 2:'lightgray'}
sns.pairplot(df_onlynum, hue='Sentiment', palette=sentiment_colors, diag_kind='kde')
<seaborn.axisgrid.PairGrid at 0x7f8d92149a80>

departments = raw_df['Department Name'].unique()
fig, axes = plt.subplots(nrows=1, ncols=len(departments)-1, figsize=(15, 5))
for i, department in enumerate(departments):
department_df = raw_df[raw_df['Department Name'] == department]
if not department_df['Sentiment'].empty:
sns.countplot(x='Sentiment', data=department_df, palette=sentiment_colors, ax=axes[i])
axes[i].set_title(f'{department}')
axes[i].set_xticklabels(axes[i].get_xticklabels(), rotation=45) # Rotate x-axis labels
sns.despine(ax=axes[i])
plt.tight_layout()
plt.show()

fig, axes = plt.subplots(nrows=1, ncols=len(departments)-1, figsize=(15, 5))
max_count = raw_df.groupby('Sentiment').size().max()
for i, department in enumerate(departments):
department_df = raw_df[raw_df['Department Name'] == department]
if not department_df['Sentiment'].empty:
sns.countplot(x='Sentiment', data=department_df, palette=sentiment_colors, ax=axes[i])
axes[i].set_title(f'{department}')
axes[i].set_xticklabels(axes[i].get_xticklabels(), rotation=45) # Rotate x-axis labels
axes[i].set_ylim(0, 8000) # Set the y-axis limit
sns.despine(ax=axes[i])
plt.tight_layout()
plt.show()

divisions = raw_df['Division Name'].unique()
fig, axes = plt.subplots(nrows=1, ncols=len(divisions)-1, figsize=(15, 5))
for i, division in enumerate(divisions):
department_df = raw_df[raw_df['Division Name'] == division]
if not department_df['Sentiment'].empty:
sns.countplot(x='Sentiment', data=department_df, palette=sentiment_colors, ax=axes[i])
axes[i].set_title(f'{division}')
axes[i].set_xticklabels(axes[i].get_xticklabels(), rotation=45) # Rotate x-axis labels
sns.despine(ax=axes[i])
plt.tight_layout()
plt.show()

divisions = raw_df['Division Name'].unique()
fig, axes = plt.subplots(nrows=1, ncols=len(divisions)-1, figsize=(15, 5))
for i, division in enumerate(divisions):
department_df = raw_df[raw_df['Division Name'] == division]
if not department_df['Sentiment'].empty:
sns.countplot(x='Sentiment', data=department_df, palette=sentiment_colors, ax=axes[i])
axes[i].set_title(f'{division}')
axes[i].set_xticklabels(axes[i].get_xticklabels(), rotation=45) # Rotate x-axis labels
axes[i].set_ylim(0, 11000)
sns.despine(ax=axes[i])
plt.tight_layout()
plt.show()

Data Exploration Discussion
From the graphs above, we see that different reviews (positive, negative, neutral) were given by all customers regardless of age. We also see a comparitively high number of positive reviews, compared to neutral and negative reviews. This is the case for all Departments, and even for all Divisions. The top 3 departments are the Tops, Dresses, and Bottoms, in order, giving them more reviews than other departments.
Split the dataset
The dataset was split into the train-validation (80%) and test (20%) sets.
Use only `Review Text` and `Sentiment` features.
senti_df = raw_df[['Review Text', 'Sentiment']]
print(f'Dataframe of reviews with only Text and Sentiment columns has {senti_df.shape} shape')
Dataframe of reviews with only Text and Sentiment columns has (22641, 2) shape
Split to 20% test set
X = senti_df.drop('Sentiment', axis=1)
y = senti_df['Sentiment']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=42)
print(f'Training set contains: {len(X_train)} rows')
print(f'Test set contains: {len(X_test)} rows')
Training set contains: 18112 rows Test set contains: 4529 rows
Lemmatize the reviews
To optimize the performance of the custom trained model, the train Review Text was lemmatized, turning words into their base form.
X_train['Review Text'] = X_train['Review Text'].apply(lemmatize_text)
Undersample
The training data was imbalanced with a majority of 76% positive reviews. To remove unintentional bias from the model, the training data was resampled using the Random Undersampler from Imblearn.
Sentiment Distribution
senti_counts = senti_df['Sentiment'].value_counts()
total_senti = len(senti_df['Sentiment'])
senti_100 = senti_counts / total_senti * 100
senti_ct = pd.DataFrame({
'Sentiment': senti_counts.index,
'Count': senti_counts.values,
'Percentage': senti_100.values.round(2)
})
senti_ct
| Sentiment | Count | Percentage | |
|---|---|---|---|
| 0 | 3 | 17261 | 76.24 |
| 1 | 2 | 3119 | 13.78 |
| 2 | 1 | 2261 | 9.99 |
ax = senti_counts.plot(kind='barh', color=['orange', 'lightgrey', 'black'])
for index, value in enumerate(senti_counts):
ax.text(value, index, str(value))
plt.title('Sentiment Distribution')
plt.xlabel('Count')
plt.ylabel('Sentiment')
plt.show()

Random Undersampling
For computational efficiency, random undersampling was utilized, equalizing the distribution of positive, neutral and negative reviews.
undersampler = RandomUnderSampler(random_state=42)
X_resampled, y_resampled = undersampler.fit_resample(X_train, y_train)
class_counts_before = pd.Series(y_train).value_counts()
class_counts_after = pd.Series(y_resampled).value_counts()
print("Before Undersampling:")
print(class_counts_before, '\n')
compute_pcc(senti_df)
print('-'*20)
print("\nAfter Undersampling:")
print(class_counts_after, '\n')
compute_pcc(y_resampled.to_frame())
Before Undersampling: Sentiment 3 13806 2 2474 1 1832 Name: count, dtype: int64 Proportion Chance Criterion: 61.02 1.25 * Proportion Chance Criterion: 76.27 -------------------- After Undersampling: Sentiment 1 1832 2 1832 3 1832 Name: count, dtype: int64 Proportion Chance Criterion: 33.33 1.25 * Proportion Chance Criterion: 41.67
Count Vectorizer
The text in the Review Text was vectorized to enable processing. English stop words were used to remove common words. Only words considered were those in atleast 5 documents, and at most at 80% of the documents to remove the "noise" (words) from the data. Only words considered were alphabetic characters with atleast 2 letters.
countvec = CountVectorizer(
stop_words='english',
token_pattern=r'\b[a-z]{2,}\b',
lowercase=True,
min_df=5,
max_df=.8
)
X_resampled_countvec = countvec.fit_transform(X_resampled['Review Text'])
X_test_countvec = countvec.transform(X_test['Review Text'])
feature_names = countvec.get_feature_names_out()
print(f'Number of features (words): {len(feature_names)}')
Number of features (words): 1810
Grid Search
GridSearch was used to find the best model and best parameter to use. Different classifiers were tried including Logistic Regession, Linear Support Vector Machine, K Neighbors Classifer, Random Forest Classifier, Gradient Boosting Classifer, and Multinomial Naive Bayes.
C_range = [1.e-05, 1.e-03, 1.e-01, 1.e+01, 1.e+03, 1.e+05]
alpha_range = [1.e-05, 1.e-03, 1.e-01, 1.0, 1.e+01, 1.e+03, 1.e+05]
max_depth_range = [5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]
learning_rate_range = [0.1, 0.5, 1.0]
n_neighbor_range = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
pipe = Pipeline([('clf', None)])
param_grid = [
{'clf': [LogisticRegression()],
'clf__penalty': ['l1', 'l2'],
'clf__C': C_range,
'clf__solver': ['liblinear']},
{'clf': [LinearSVC()],
'clf__penalty': ['l1', 'l2'],
'clf__C': C_range,
'clf__dual': [False]},
{'clf': [KNeighborsClassifier()],
'clf__n_neighbors': n_neighbor_range},
{'clf': [RandomForestClassifier()],
'clf__max_depth': max_depth_range},
{'clf': [GradientBoostingClassifier()],
'clf__learning_rate': learning_rate_range,
'clf__max_depth': max_depth_range},
{'clf': [MultinomialNB()],
'clf__alpha': alpha_range,
}
]
grid_search = GridSearchCV(pipe, param_grid, cv=5, return_train_score=True,
scoring='accuracy', verbose=3, error_score='raise')
grid_search.fit(X_resampled_countvec, y_resampled)
Fitting 5 folds for each of 85 candidates, totalling 425 fits [CV 1/5] END clf=LogisticRegression(), clf__C=1e-05, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.167, test=1.000) total time= 0.0s [CV 2/5] END clf=LogisticRegression(), clf__C=1e-05, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.250, test=0.666) total time= 0.0s [CV 3/5] END clf=LogisticRegression(), clf__C=1e-05, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.417, test=0.000) total time= 0.0s [CV 4/5] END clf=LogisticRegression(), clf__C=1e-05, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.417, test=0.000) total time= 0.0s [CV 5/5] END clf=LogisticRegression(), clf__C=1e-05, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.417, test=0.000) total time= 0.0s [CV 1/5] END clf=LogisticRegression(), clf__C=1e-05, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.614, test=0.000) total time= 0.0s [CV 2/5] END clf=LogisticRegression(), clf__C=1e-05, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.423, test=0.004) total time= 0.0s [CV 3/5] END clf=LogisticRegression(), clf__C=1e-05, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.644, test=0.000) total time= 0.0s [CV 4/5] END clf=LogisticRegression(), clf__C=1e-05, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.417, test=0.000) total time= 0.0s [CV 5/5] END clf=LogisticRegression(), clf__C=1e-05, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.503, test=0.000) total time= 0.0s [CV 1/5] END clf=LogisticRegression(), clf__C=0.001, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.417, test=0.000) total time= 0.0s [CV 2/5] END clf=LogisticRegression(), clf__C=0.001, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.333, test=0.334) total time= 0.0s [CV 3/5] END clf=LogisticRegression(), clf__C=0.001, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.417, test=0.000) total time= 0.0s [CV 4/5] END clf=LogisticRegression(), clf__C=0.001, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.417, test=0.000) total time= 0.0s [CV 5/5] END clf=LogisticRegression(), clf__C=0.001, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.417, test=0.000) total time= 0.0s [CV 1/5] END clf=LogisticRegression(), clf__C=0.001, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.624, test=0.000) total time= 0.0s [CV 2/5] END clf=LogisticRegression(), clf__C=0.001, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.545, test=0.155) total time= 0.0s [CV 3/5] END clf=LogisticRegression(), clf__C=0.001, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.675, test=0.000) total time= 0.0s [CV 4/5] END clf=LogisticRegression(), clf__C=0.001, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.538, test=0.268) total time= 0.0s [CV 5/5] END clf=LogisticRegression(), clf__C=0.001, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.558, test=0.002) total time= 0.0s [CV 1/5] END clf=LogisticRegression(), clf__C=0.1, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.658, test=0.061) total time= 0.0s [CV 2/5] END clf=LogisticRegression(), clf__C=0.1, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.643, test=0.415) total time= 0.0s [CV 3/5] END clf=LogisticRegression(), clf__C=0.1, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.709, test=0.004) total time= 0.0s [CV 4/5] END clf=LogisticRegression(), clf__C=0.1, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.615, test=0.528) total time= 0.0s [CV 5/5] END clf=LogisticRegression(), clf__C=0.1, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.609, test=0.368) total time= 0.0s [CV 1/5] END clf=LogisticRegression(), clf__C=0.1, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.764, test=0.196) total time= 0.1s [CV 2/5] END clf=LogisticRegression(), clf__C=0.1, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.775, test=0.468) total time= 0.1s [CV 3/5] END clf=LogisticRegression(), clf__C=0.1, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.796, test=0.076) total time= 0.1s [CV 4/5] END clf=LogisticRegression(), clf__C=0.1, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.751, test=0.583) total time= 0.1s [CV 5/5] END clf=LogisticRegression(), clf__C=0.1, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.741, test=0.495) total time= 0.1s [CV 1/5] END clf=LogisticRegression(), clf__C=10.0, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.964, test=0.350) total time= 0.2s [CV 2/5] END clf=LogisticRegression(), clf__C=10.0, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.960, test=0.449) total time= 0.2s [CV 3/5] END clf=LogisticRegression(), clf__C=10.0, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.975, test=0.255) total time= 0.2s [CV 4/5] END clf=LogisticRegression(), clf__C=10.0, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.938, test=0.540) total time= 0.2s [CV 5/5] END clf=LogisticRegression(), clf__C=10.0, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.925, test=0.506) total time= 0.1s [CV 1/5] END clf=LogisticRegression(), clf__C=10.0, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.935, test=0.345) total time= 0.4s [CV 2/5] END clf=LogisticRegression(), clf__C=10.0, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.935, test=0.452) total time= 0.4s [CV 3/5] END clf=LogisticRegression(), clf__C=10.0, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.958, test=0.226) total time= 0.4s [CV 4/5] END clf=LogisticRegression(), clf__C=10.0, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.915, test=0.576) total time= 0.5s [CV 5/5] END clf=LogisticRegression(), clf__C=10.0, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.904, test=0.517) total time= 0.4s [CV 1/5] END clf=LogisticRegression(), clf__C=1000.0, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.996, test=0.329) total time= 2.3s [CV 2/5] END clf=LogisticRegression(), clf__C=1000.0, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.994, test=0.439) total time= 1.0s [CV 3/5] END clf=LogisticRegression(), clf__C=1000.0, clf__penalty=l1, clf__solver=liblinear;, score=(train=1.000, test=0.282) total time= 1.4s [CV 4/5] END clf=LogisticRegression(), clf__C=1000.0, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.985, test=0.494) total time= 12.1s [CV 5/5] END clf=LogisticRegression(), clf__C=1000.0, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.975, test=0.439) total time= 21.8s [CV 1/5] END clf=LogisticRegression(), clf__C=1000.0, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.991, test=0.358) total time= 1.7s [CV 2/5] END clf=LogisticRegression(), clf__C=1000.0, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.984, test=0.440) total time= 2.0s [CV 3/5] END clf=LogisticRegression(), clf__C=1000.0, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.996, test=0.268) total time= 1.4s [CV 4/5] END clf=LogisticRegression(), clf__C=1000.0, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.971, test=0.520) total time= 2.1s [CV 5/5] END clf=LogisticRegression(), clf__C=1000.0, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.954, test=0.470) total time= 1.8s [CV 1/5] END clf=LogisticRegression(), clf__C=100000.0, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.997, test=0.319) total time= 2.7s [CV 2/5] END clf=LogisticRegression(), clf__C=100000.0, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.997, test=0.425) total time= 1.1s [CV 3/5] END clf=LogisticRegression(), clf__C=100000.0, clf__penalty=l1, clf__solver=liblinear;, score=(train=1.000, test=0.278) total time= 0.7s [CV 4/5] END clf=LogisticRegression(), clf__C=100000.0, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.984, test=0.485) total time= 10.8s [CV 5/5] END clf=LogisticRegression(), clf__C=100000.0, clf__penalty=l1, clf__solver=liblinear;, score=(train=0.975, test=0.440) total time= 19.2s [CV 1/5] END clf=LogisticRegression(), clf__C=100000.0, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.999, test=0.370) total time= 2.0s [CV 2/5] END clf=LogisticRegression(), clf__C=100000.0, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.996, test=0.433) total time= 3.6s [CV 3/5] END clf=LogisticRegression(), clf__C=100000.0, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.999, test=0.267) total time= 2.0s [CV 4/5] END clf=LogisticRegression(), clf__C=100000.0, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.985, test=0.491) total time= 5.5s [CV 5/5] END clf=LogisticRegression(), clf__C=100000.0, clf__penalty=l2, clf__solver=liblinear;, score=(train=0.974, test=0.463) total time= 4.4s [CV 1/5] END clf=LinearSVC(), clf__C=1e-05, clf__dual=False, clf__penalty=l1;, score=(train=0.167, test=1.000) total time= 0.0s [CV 2/5] END clf=LinearSVC(), clf__C=1e-05, clf__dual=False, clf__penalty=l1;, score=(train=0.250, test=0.666) total time= 0.0s [CV 3/5] END clf=LinearSVC(), clf__C=1e-05, clf__dual=False, clf__penalty=l1;, score=(train=0.417, test=0.000) total time= 0.0s [CV 4/5] END clf=LinearSVC(), clf__C=1e-05, clf__dual=False, clf__penalty=l1;, score=(train=0.417, test=0.000) total time= 0.0s [CV 5/5] END clf=LinearSVC(), clf__C=1e-05, clf__dual=False, clf__penalty=l1;, score=(train=0.417, test=0.000) total time= 0.0s [CV 1/5] END clf=LinearSVC(), clf__C=1e-05, clf__dual=False, clf__penalty=l2;, score=(train=0.614, test=0.000) total time= 0.0s [CV 2/5] END clf=LinearSVC(), clf__C=1e-05, clf__dual=False, clf__penalty=l2;, score=(train=0.437, test=0.017) total time= 0.0s [CV 3/5] END clf=LinearSVC(), clf__C=1e-05, clf__dual=False, clf__penalty=l2;, score=(train=0.652, test=0.000) total time= 0.0s [CV 4/5] END clf=LinearSVC(), clf__C=1e-05, clf__dual=False, clf__penalty=l2;, score=(train=0.418, test=0.002) total time= 0.0s [CV 5/5] END clf=LinearSVC(), clf__C=1e-05, clf__dual=False, clf__penalty=l2;, score=(train=0.521, test=0.000) total time= 0.0s [CV 1/5] END clf=LinearSVC(), clf__C=0.001, clf__dual=False, clf__penalty=l1;, score=(train=0.456, test=0.000) total time= 0.0s [CV 2/5] END clf=LinearSVC(), clf__C=0.001, clf__dual=False, clf__penalty=l1;, score=(train=0.418, test=0.001) total time= 0.0s [CV 3/5] END clf=LinearSVC(), clf__C=0.001, clf__dual=False, clf__penalty=l1;, score=(train=0.479, test=0.000) total time= 0.0s [CV 4/5] END clf=LinearSVC(), clf__C=0.001, clf__dual=False, clf__penalty=l1;, score=(train=0.417, test=0.000) total time= 0.0s [CV 5/5] END clf=LinearSVC(), clf__C=0.001, clf__dual=False, clf__penalty=l1;, score=(train=0.417, test=0.000) total time= 0.0s [CV 1/5] END clf=LinearSVC(), clf__C=0.001, clf__dual=False, clf__penalty=l2;, score=(train=0.664, test=0.018) total time= 0.0s [CV 2/5] END clf=LinearSVC(), clf__C=0.001, clf__dual=False, clf__penalty=l2;, score=(train=0.668, test=0.382) total time= 0.0s [CV 3/5] END clf=LinearSVC(), clf__C=0.001, clf__dual=False, clf__penalty=l2;, score=(train=0.722, test=0.000) total time= 0.0s [CV 4/5] END clf=LinearSVC(), clf__C=0.001, clf__dual=False, clf__penalty=l2;, score=(train=0.644, test=0.523) total time= 0.0s [CV 5/5] END clf=LinearSVC(), clf__C=0.001, clf__dual=False, clf__penalty=l2;, score=(train=0.645, test=0.307) total time= 0.0s [CV 1/5] END clf=LinearSVC(), clf__C=0.1, clf__dual=False, clf__penalty=l1;, score=(train=0.744, test=0.180) total time= 0.1s [CV 2/5] END clf=LinearSVC(), clf__C=0.1, clf__dual=False, clf__penalty=l1;, score=(train=0.744, test=0.467) total time= 0.1s [CV 3/5] END clf=LinearSVC(), clf__C=0.1, clf__dual=False, clf__penalty=l1;, score=(train=0.774, test=0.048) total time= 0.1s [CV 4/5] END clf=LinearSVC(), clf__C=0.1, clf__dual=False, clf__penalty=l1;, score=(train=0.719, test=0.589) total time= 0.1s [CV 5/5] END clf=LinearSVC(), clf__C=0.1, clf__dual=False, clf__penalty=l1;, score=(train=0.714, test=0.480) total time= 0.1s [CV 1/5] END clf=LinearSVC(), clf__C=0.1, clf__dual=False, clf__penalty=l2;, score=(train=0.863, test=0.303) total time= 0.2s [CV 2/5] END clf=LinearSVC(), clf__C=0.1, clf__dual=False, clf__penalty=l2;, score=(train=0.866, test=0.458) total time= 0.2s [CV 3/5] END clf=LinearSVC(), clf__C=0.1, clf__dual=False, clf__penalty=l2;, score=(train=0.885, test=0.156) total time= 0.1s [CV 4/5] END clf=LinearSVC(), clf__C=0.1, clf__dual=False, clf__penalty=l2;, score=(train=0.849, test=0.585) total time= 0.2s [CV 5/5] END clf=LinearSVC(), clf__C=0.1, clf__dual=False, clf__penalty=l2;, score=(train=0.838, test=0.544) total time= 0.2s [CV 1/5] END clf=LinearSVC(), clf__C=10.0, clf__dual=False, clf__penalty=l1;, score=(train=0.982, test=0.340) total time= 3.3s [CV 2/5] END clf=LinearSVC(), clf__C=10.0, clf__dual=False, clf__penalty=l1;, score=(train=0.978, test=0.443) total time= 3.2s [CV 3/5] END clf=LinearSVC(), clf__C=10.0, clf__dual=False, clf__penalty=l1;, score=(train=0.991, test=0.273) total time= 3.3s [CV 4/5] END clf=LinearSVC(), clf__C=10.0, clf__dual=False, clf__penalty=l1;, score=(train=0.960, test=0.515) total time= 3.2s [CV 5/5] END clf=LinearSVC(), clf__C=10.0, clf__dual=False, clf__penalty=l1;, score=(train=0.941, test=0.475) total time= 2.8s [CV 1/5] END clf=LinearSVC(), clf__C=10.0, clf__dual=False, clf__penalty=l2;, score=(train=0.974, test=0.359) total time= 2.3s [CV 2/5] END clf=LinearSVC(), clf__C=10.0, clf__dual=False, clf__penalty=l2;, score=(train=0.971, test=0.449) total time= 3.3s [CV 3/5] END clf=LinearSVC(), clf__C=10.0, clf__dual=False, clf__penalty=l2;, score=(train=0.985, test=0.280) total time= 2.9s [CV 4/5] END clf=LinearSVC(), clf__C=10.0, clf__dual=False, clf__penalty=l2;, score=(train=0.950, test=0.526) total time= 2.6s [CV 5/5] END clf=LinearSVC(), clf__C=10.0, clf__dual=False, clf__penalty=l2;, score=(train=0.933, test=0.489) total time= 2.0s [CV 1/5] END clf=LinearSVC(), clf__C=1000.0, clf__dual=False, clf__penalty=l1;, score=(train=0.992, test=0.334) total time= 3.7s [CV 2/5] END clf=LinearSVC(), clf__C=1000.0, clf__dual=False, clf__penalty=l1;, score=(train=0.990, test=0.435) total time= 3.5s [CV 3/5] END clf=LinearSVC(), clf__C=1000.0, clf__dual=False, clf__penalty=l1;, score=(train=1.000, test=0.272) total time= 3.4s [CV 4/5] END clf=LinearSVC(), clf__C=1000.0, clf__dual=False, clf__penalty=l1;, score=(train=0.974, test=0.494) total time= 3.4s [CV 5/5] END clf=LinearSVC(), clf__C=1000.0, clf__dual=False, clf__penalty=l1;, score=(train=0.960, test=0.440) total time= 3.0s [CV 1/5] END clf=LinearSVC(), clf__C=1000.0, clf__dual=False, clf__penalty=l2;, score=(train=0.989, test=0.336) total time= 8.0s [CV 2/5] END clf=LinearSVC(), clf__C=1000.0, clf__dual=False, clf__penalty=l2;, score=(train=0.983, test=0.431) total time= 7.4s [CV 3/5] END clf=LinearSVC(), clf__C=1000.0, clf__dual=False, clf__penalty=l2;, score=(train=0.996, test=0.267) total time= 5.8s [CV 4/5] END clf=LinearSVC(), clf__C=1000.0, clf__dual=False, clf__penalty=l2;, score=(train=0.969, test=0.503) total time= 8.8s [CV 5/5] END clf=LinearSVC(), clf__C=1000.0, clf__dual=False, clf__penalty=l2;, score=(train=0.953, test=0.461) total time= 8.8s [CV 1/5] END clf=LinearSVC(), clf__C=100000.0, clf__dual=False, clf__penalty=l1;, score=(train=0.993, test=0.326) total time= 3.6s [CV 2/5] END clf=LinearSVC(), clf__C=100000.0, clf__dual=False, clf__penalty=l1;, score=(train=0.991, test=0.436) total time= 3.6s [CV 3/5] END clf=LinearSVC(), clf__C=100000.0, clf__dual=False, clf__penalty=l1;, score=(train=1.000, test=0.272) total time= 3.4s [CV 4/5] END clf=LinearSVC(), clf__C=100000.0, clf__dual=False, clf__penalty=l1;, score=(train=0.974, test=0.500) total time= 3.5s [CV 5/5] END clf=LinearSVC(), clf__C=100000.0, clf__dual=False, clf__penalty=l1;, score=(train=0.960, test=0.438) total time= 2.8s [CV 1/5] END clf=LinearSVC(), clf__C=100000.0, clf__dual=False, clf__penalty=l2;, score=(train=0.989, test=0.337) total time= 7.5s [CV 2/5] END clf=LinearSVC(), clf__C=100000.0, clf__dual=False, clf__penalty=l2;, score=(train=0.983, test=0.432) total time= 7.6s [CV 3/5] END clf=LinearSVC(), clf__C=100000.0, clf__dual=False, clf__penalty=l2;, score=(train=0.996, test=0.265) total time= 5.5s [CV 4/5] END clf=LinearSVC(), clf__C=100000.0, clf__dual=False, clf__penalty=l2;, score=(train=0.969, test=0.509) total time= 9.2s [CV 5/5] END clf=LinearSVC(), clf__C=100000.0, clf__dual=False, clf__penalty=l2;, score=(train=0.954, test=0.462) total time= 8.1s [CV 1/5] END clf=KNeighborsClassifier(), clf__n_neighbors=1;, score=(train=1.000, test=0.365) total time= 0.3s [CV 2/5] END clf=KNeighborsClassifier(), clf__n_neighbors=1;, score=(train=1.000, test=0.419) total time= 0.3s [CV 3/5] END clf=KNeighborsClassifier(), clf__n_neighbors=1;, score=(train=1.000, test=0.153) total time= 0.3s [CV 4/5] END clf=KNeighborsClassifier(), clf__n_neighbors=1;, score=(train=1.000, test=0.337) total time= 0.2s [CV 5/5] END clf=KNeighborsClassifier(), clf__n_neighbors=1;, score=(train=1.000, test=0.240) total time= 0.2s [CV 1/5] END clf=KNeighborsClassifier(), clf__n_neighbors=2;, score=(train=0.667, test=0.534) total time= 0.2s [CV 2/5] END clf=KNeighborsClassifier(), clf__n_neighbors=2;, score=(train=0.677, test=0.540) total time= 0.2s [CV 3/5] END clf=KNeighborsClassifier(), clf__n_neighbors=2;, score=(train=0.711, test=0.106) total time= 0.3s [CV 4/5] END clf=KNeighborsClassifier(), clf__n_neighbors=2;, score=(train=0.666, test=0.183) total time= 0.3s [CV 5/5] END clf=KNeighborsClassifier(), clf__n_neighbors=2;, score=(train=0.660, test=0.076) total time= 0.3s [CV 1/5] END clf=KNeighborsClassifier(), clf__n_neighbors=3;, score=(train=0.695, test=0.445) total time= 0.3s [CV 2/5] END clf=KNeighborsClassifier(), clf__n_neighbors=3;, score=(train=0.695, test=0.489) total time= 0.3s [CV 3/5] END clf=KNeighborsClassifier(), clf__n_neighbors=3;, score=(train=0.719, test=0.071) total time= 0.3s [CV 4/5] END clf=KNeighborsClassifier(), clf__n_neighbors=3;, score=(train=0.678, test=0.278) total time= 0.3s [CV 5/5] END clf=KNeighborsClassifier(), clf__n_neighbors=3;, score=(train=0.669, test=0.144) total time= 0.3s [CV 1/5] END clf=KNeighborsClassifier(), clf__n_neighbors=4;, score=(train=0.688, test=0.252) total time= 0.3s [CV 2/5] END clf=KNeighborsClassifier(), clf__n_neighbors=4;, score=(train=0.697, test=0.342) total time= 0.3s [CV 3/5] END clf=KNeighborsClassifier(), clf__n_neighbors=4;, score=(train=0.723, test=0.104) total time= 0.3s [CV 4/5] END clf=KNeighborsClassifier(), clf__n_neighbors=4;, score=(train=0.668, test=0.372) total time= 0.3s [CV 5/5] END clf=KNeighborsClassifier(), clf__n_neighbors=4;, score=(train=0.651, test=0.222) total time= 0.2s [CV 1/5] END clf=KNeighborsClassifier(), clf__n_neighbors=5;, score=(train=0.670, test=0.281) total time= 0.3s [CV 2/5] END clf=KNeighborsClassifier(), clf__n_neighbors=5;, score=(train=0.665, test=0.356) total time= 0.3s [CV 3/5] END clf=KNeighborsClassifier(), clf__n_neighbors=5;, score=(train=0.700, test=0.097) total time= 0.3s [CV 4/5] END clf=KNeighborsClassifier(), clf__n_neighbors=5;, score=(train=0.652, test=0.373) total time= 0.3s [CV 5/5] END clf=KNeighborsClassifier(), clf__n_neighbors=5;, score=(train=0.632, test=0.169) total time= 0.3s [CV 1/5] END clf=KNeighborsClassifier(), clf__n_neighbors=6;, score=(train=0.653, test=0.269) total time= 0.3s [CV 2/5] END clf=KNeighborsClassifier(), clf__n_neighbors=6;, score=(train=0.640, test=0.318) total time= 0.3s [CV 3/5] END clf=KNeighborsClassifier(), clf__n_neighbors=6;, score=(train=0.681, test=0.062) total time= 0.3s [CV 4/5] END clf=KNeighborsClassifier(), clf__n_neighbors=6;, score=(train=0.639, test=0.374) total time= 0.3s [CV 5/5] END clf=KNeighborsClassifier(), clf__n_neighbors=6;, score=(train=0.618, test=0.199) total time= 0.3s [CV 1/5] END clf=KNeighborsClassifier(), clf__n_neighbors=7;, score=(train=0.644, test=0.203) total time= 0.3s [CV 2/5] END clf=KNeighborsClassifier(), clf__n_neighbors=7;, score=(train=0.629, test=0.308) total time= 0.3s [CV 3/5] END clf=KNeighborsClassifier(), clf__n_neighbors=7;, score=(train=0.672, test=0.066) total time= 0.3s [CV 4/5] END clf=KNeighborsClassifier(), clf__n_neighbors=7;, score=(train=0.625, test=0.396) total time= 0.3s [CV 5/5] END clf=KNeighborsClassifier(), clf__n_neighbors=7;, score=(train=0.606, test=0.193) total time= 0.3s [CV 1/5] END clf=KNeighborsClassifier(), clf__n_neighbors=8;, score=(train=0.646, test=0.220) total time= 0.3s [CV 2/5] END clf=KNeighborsClassifier(), clf__n_neighbors=8;, score=(train=0.623, test=0.309) total time= 0.3s [CV 3/5] END clf=KNeighborsClassifier(), clf__n_neighbors=8;, score=(train=0.660, test=0.056) total time= 0.3s [CV 4/5] END clf=KNeighborsClassifier(), clf__n_neighbors=8;, score=(train=0.612, test=0.362) total time= 0.3s [CV 5/5] END clf=KNeighborsClassifier(), clf__n_neighbors=8;, score=(train=0.591, test=0.183) total time= 0.3s [CV 1/5] END clf=KNeighborsClassifier(), clf__n_neighbors=9;, score=(train=0.638, test=0.210) total time= 0.3s [CV 2/5] END clf=KNeighborsClassifier(), clf__n_neighbors=9;, score=(train=0.614, test=0.298) total time= 0.3s [CV 3/5] END clf=KNeighborsClassifier(), clf__n_neighbors=9;, score=(train=0.657, test=0.042) total time= 0.3s [CV 4/5] END clf=KNeighborsClassifier(), clf__n_neighbors=9;, score=(train=0.600, test=0.385) total time= 0.3s [CV 5/5] END clf=KNeighborsClassifier(), clf__n_neighbors=9;, score=(train=0.591, test=0.196) total time= 0.3s [CV 1/5] END clf=KNeighborsClassifier(), clf__n_neighbors=10;, score=(train=0.634, test=0.185) total time= 0.3s [CV 2/5] END clf=KNeighborsClassifier(), clf__n_neighbors=10;, score=(train=0.598, test=0.290) total time= 0.3s [CV 3/5] END clf=KNeighborsClassifier(), clf__n_neighbors=10;, score=(train=0.654, test=0.041) total time= 0.3s [CV 4/5] END clf=KNeighborsClassifier(), clf__n_neighbors=10;, score=(train=0.605, test=0.390) total time= 0.3s [CV 5/5] END clf=KNeighborsClassifier(), clf__n_neighbors=10;, score=(train=0.585, test=0.195) total time= 0.3s [CV 1/5] END clf=RandomForestClassifier(), clf__max_depth=5;, score=(train=0.661, test=0.000) total time= 0.3s [CV 2/5] END clf=RandomForestClassifier(), clf__max_depth=5;, score=(train=0.471, test=0.038) total time= 0.3s [CV 3/5] END clf=RandomForestClassifier(), clf__max_depth=5;, score=(train=0.709, test=0.000) total time= 0.3s [CV 4/5] END clf=RandomForestClassifier(), clf__max_depth=5;, score=(train=0.443, test=0.060) total time= 0.3s [CV 5/5] END clf=RandomForestClassifier(), clf__max_depth=5;, score=(train=0.595, test=0.000) total time= 0.3s [CV 1/5] END clf=RandomForestClassifier(), clf__max_depth=6;, score=(train=0.669, test=0.000) total time= 0.3s [CV 2/5] END clf=RandomForestClassifier(), clf__max_depth=6;, score=(train=0.499, test=0.063) total time= 0.3s [CV 3/5] END clf=RandomForestClassifier(), clf__max_depth=6;, score=(train=0.714, test=0.000) total time= 0.3s [CV 4/5] END clf=RandomForestClassifier(), clf__max_depth=6;, score=(train=0.470, test=0.098) total time= 0.3s [CV 5/5] END clf=RandomForestClassifier(), clf__max_depth=6;, score=(train=0.608, test=0.002) total time= 0.3s [CV 1/5] END clf=RandomForestClassifier(), clf__max_depth=7;, score=(train=0.684, test=0.000) total time= 0.3s [CV 2/5] END clf=RandomForestClassifier(), clf__max_depth=7;, score=(train=0.529, test=0.091) total time= 0.3s [CV 3/5] END clf=RandomForestClassifier(), clf__max_depth=7;, score=(train=0.728, test=0.000) total time= 0.3s [CV 4/5] END clf=RandomForestClassifier(), clf__max_depth=7;, score=(train=0.502, test=0.156) total time= 0.3s [CV 5/5] END clf=RandomForestClassifier(), clf__max_depth=7;, score=(train=0.632, test=0.005) total time= 0.3s [CV 1/5] END clf=RandomForestClassifier(), clf__max_depth=8;, score=(train=0.697, test=0.000) total time= 0.3s [CV 2/5] END clf=RandomForestClassifier(), clf__max_depth=8;, score=(train=0.567, test=0.110) total time= 0.3s [CV 3/5] END clf=RandomForestClassifier(), clf__max_depth=8;, score=(train=0.736, test=0.000) total time= 0.3s [CV 4/5] END clf=RandomForestClassifier(), clf__max_depth=8;, score=(train=0.532, test=0.182) total time= 0.3s [CV 5/5] END clf=RandomForestClassifier(), clf__max_depth=8;, score=(train=0.660, test=0.013) total time= 0.3s [CV 1/5] END clf=RandomForestClassifier(), clf__max_depth=9;, score=(train=0.703, test=0.000) total time= 0.4s [CV 2/5] END clf=RandomForestClassifier(), clf__max_depth=9;, score=(train=0.596, test=0.142) total time= 0.3s [CV 3/5] END clf=RandomForestClassifier(), clf__max_depth=9;, score=(train=0.735, test=0.000) total time= 0.3s [CV 4/5] END clf=RandomForestClassifier(), clf__max_depth=9;, score=(train=0.562, test=0.224) total time= 0.3s [CV 5/5] END clf=RandomForestClassifier(), clf__max_depth=9;, score=(train=0.671, test=0.019) total time= 0.3s [CV 1/5] END clf=RandomForestClassifier(), clf__max_depth=10;, score=(train=0.707, test=0.000) total time= 0.4s [CV 2/5] END clf=RandomForestClassifier(), clf__max_depth=10;, score=(train=0.635, test=0.141) total time= 0.4s [CV 3/5] END clf=RandomForestClassifier(), clf__max_depth=10;, score=(train=0.743, test=0.000) total time= 0.4s [CV 4/5] END clf=RandomForestClassifier(), clf__max_depth=10;, score=(train=0.595, test=0.255) total time= 0.4s [CV 5/5] END clf=RandomForestClassifier(), clf__max_depth=10;, score=(train=0.695, test=0.041) total time= 0.4s [CV 1/5] END clf=RandomForestClassifier(), clf__max_depth=11;, score=(train=0.726, test=0.000) total time= 0.4s [CV 2/5] END clf=RandomForestClassifier(), clf__max_depth=11;, score=(train=0.675, test=0.192) total time= 0.4s [CV 3/5] END clf=RandomForestClassifier(), clf__max_depth=11;, score=(train=0.749, test=0.000) total time= 0.4s [CV 4/5] END clf=RandomForestClassifier(), clf__max_depth=11;, score=(train=0.627, test=0.270) total time= 0.4s [CV 5/5] END clf=RandomForestClassifier(), clf__max_depth=11;, score=(train=0.718, test=0.040) total time= 0.4s [CV 1/5] END clf=RandomForestClassifier(), clf__max_depth=12;, score=(train=0.731, test=0.000) total time= 0.5s [CV 2/5] END clf=RandomForestClassifier(), clf__max_depth=12;, score=(train=0.708, test=0.213) total time= 0.5s [CV 3/5] END clf=RandomForestClassifier(), clf__max_depth=12;, score=(train=0.756, test=0.000) total time= 0.5s [CV 4/5] END clf=RandomForestClassifier(), clf__max_depth=12;, score=(train=0.662, test=0.309) total time= 0.5s [CV 5/5] END clf=RandomForestClassifier(), clf__max_depth=12;, score=(train=0.735, test=0.053) total time= 0.4s [CV 1/5] END clf=RandomForestClassifier(), clf__max_depth=13;, score=(train=0.748, test=0.000) total time= 0.5s [CV 2/5] END clf=RandomForestClassifier(), clf__max_depth=13;, score=(train=0.735, test=0.242) total time= 0.5s [CV 3/5] END clf=RandomForestClassifier(), clf__max_depth=13;, score=(train=0.765, test=0.000) total time= 0.5s [CV 4/5] END clf=RandomForestClassifier(), clf__max_depth=13;, score=(train=0.706, test=0.331) total time= 0.5s [CV 5/5] END clf=RandomForestClassifier(), clf__max_depth=13;, score=(train=0.755, test=0.069) total time= 0.5s [CV 1/5] END clf=RandomForestClassifier(), clf__max_depth=14;, score=(train=0.751, test=0.000) total time= 0.6s [CV 2/5] END clf=RandomForestClassifier(), clf__max_depth=14;, score=(train=0.763, test=0.241) total time= 0.6s [CV 3/5] END clf=RandomForestClassifier(), clf__max_depth=14;, score=(train=0.777, test=0.000) total time= 0.6s [CV 4/5] END clf=RandomForestClassifier(), clf__max_depth=14;, score=(train=0.727, test=0.359) total time= 0.6s [CV 5/5] END clf=RandomForestClassifier(), clf__max_depth=14;, score=(train=0.778, test=0.066) total time= 0.5s [CV 1/5] END clf=RandomForestClassifier(), clf__max_depth=15;, score=(train=0.770, test=0.000) total time= 0.6s [CV 2/5] END clf=RandomForestClassifier(), clf__max_depth=15;, score=(train=0.780, test=0.268) total time= 0.6s [CV 3/5] END clf=RandomForestClassifier(), clf__max_depth=15;, score=(train=0.786, test=0.000) total time= 0.7s [CV 4/5] END clf=RandomForestClassifier(), clf__max_depth=15;, score=(train=0.761, test=0.368) total time= 0.6s [CV 5/5] END clf=RandomForestClassifier(), clf__max_depth=15;, score=(train=0.798, test=0.089) total time= 0.6s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=5;, score=(train=0.839, test=0.157) total time= 6.1s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=5;, score=(train=0.846, test=0.439) total time= 6.1s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=5;, score=(train=0.846, test=0.033) total time= 5.9s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=5;, score=(train=0.838, test=0.539) total time= 6.1s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=5;, score=(train=0.840, test=0.369) total time= 6.0s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=6;, score=(train=0.883, test=0.161) total time= 7.7s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=6;, score=(train=0.897, test=0.440) total time= 7.9s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=6;, score=(train=0.888, test=0.042) total time= 7.5s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=6;, score=(train=0.892, test=0.539) total time= 7.8s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=6;, score=(train=0.886, test=0.388) total time= 7.8s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=7;, score=(train=0.910, test=0.169) total time= 9.5s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=7;, score=(train=0.933, test=0.453) total time= 9.9s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=7;, score=(train=0.916, test=0.051) total time= 9.4s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=7;, score=(train=0.924, test=0.541) total time= 9.7s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=7;, score=(train=0.913, test=0.386) total time= 9.2s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=8;, score=(train=0.938, test=0.188) total time= 11.6s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=8;, score=(train=0.952, test=0.459) total time= 11.9s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=8;, score=(train=0.939, test=0.056) total time= 11.7s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=8;, score=(train=0.948, test=0.549) total time= 11.7s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=8;, score=(train=0.940, test=0.387) total time= 11.5s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=9;, score=(train=0.954, test=0.184) total time= 14.2s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=9;, score=(train=0.967, test=0.455) total time= 14.7s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=9;, score=(train=0.956, test=0.061) total time= 13.9s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=9;, score=(train=0.962, test=0.544) total time= 14.3s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=9;, score=(train=0.956, test=0.391) total time= 13.4s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=10;, score=(train=0.969, test=0.171) total time= 16.8s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=10;, score=(train=0.978, test=0.460) total time= 17.2s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=10;, score=(train=0.970, test=0.068) total time= 16.8s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=10;, score=(train=0.970, test=0.540) total time= 16.5s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=10;, score=(train=0.967, test=0.394) total time= 15.6s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=11;, score=(train=0.977, test=0.175) total time= 19.1s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=11;, score=(train=0.985, test=0.450) total time= 20.3s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=11;, score=(train=0.976, test=0.062) total time= 19.3s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=11;, score=(train=0.978, test=0.545) total time= 19.5s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=11;, score=(train=0.977, test=0.384) total time= 19.0s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=12;, score=(train=0.983, test=0.176) total time= 22.2s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=12;, score=(train=0.989, test=0.457) total time= 23.3s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=12;, score=(train=0.984, test=0.073) total time= 22.5s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=12;, score=(train=0.983, test=0.549) total time= 22.2s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=12;, score=(train=0.984, test=0.383) total time= 21.6s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=13;, score=(train=0.985, test=0.165) total time= 25.3s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=13;, score=(train=0.993, test=0.457) total time= 26.0s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=13;, score=(train=0.989, test=0.080) total time= 25.2s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=13;, score=(train=0.987, test=0.532) total time= 25.2s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=13;, score=(train=0.985, test=0.366) total time= 25.0s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=14;, score=(train=0.988, test=0.175) total time= 29.0s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=14;, score=(train=0.995, test=0.463) total time= 30.6s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=14;, score=(train=0.992, test=0.072) total time= 29.3s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=14;, score=(train=0.991, test=0.531) total time= 28.4s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=14;, score=(train=0.990, test=0.348) total time= 27.3s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=15;, score=(train=0.992, test=0.166) total time= 32.3s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=15;, score=(train=0.995, test=0.464) total time= 34.0s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=15;, score=(train=0.995, test=0.088) total time= 32.5s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=15;, score=(train=0.991, test=0.537) total time= 31.6s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.1, clf__max_depth=15;, score=(train=0.994, test=0.348) total time= 31.1s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=5;, score=(train=0.977, test=0.217) total time= 5.4s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=5;, score=(train=0.976, test=0.465) total time= 5.3s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=5;, score=(train=0.982, test=0.105) total time= 5.3s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=5;, score=(train=0.969, test=0.569) total time= 5.4s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=5;, score=(train=0.972, test=0.439) total time= 5.2s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=6;, score=(train=0.987, test=0.223) total time= 6.6s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=6;, score=(train=0.987, test=0.478) total time= 6.7s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=6;, score=(train=0.990, test=0.100) total time= 6.6s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=6;, score=(train=0.984, test=0.565) total time= 6.5s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=6;, score=(train=0.984, test=0.431) total time= 6.6s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=7;, score=(train=0.992, test=0.215) total time= 8.0s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=7;, score=(train=0.992, test=0.473) total time= 7.9s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=7;, score=(train=0.993, test=0.104) total time= 7.9s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=7;, score=(train=0.989, test=0.565) total time= 7.8s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=7;, score=(train=0.992, test=0.415) total time= 8.0s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=8;, score=(train=0.995, test=0.221) total time= 9.5s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=8;, score=(train=0.996, test=0.459) total time= 9.8s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=8;, score=(train=0.998, test=0.101) total time= 9.8s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=8;, score=(train=0.995, test=0.569) total time= 9.3s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=8;, score=(train=0.994, test=0.397) total time= 9.3s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=9;, score=(train=0.998, test=0.202) total time= 11.1s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=9;, score=(train=0.998, test=0.476) total time= 11.3s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=9;, score=(train=0.999, test=0.096) total time= 11.0s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=9;, score=(train=0.998, test=0.555) total time= 11.1s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=9;, score=(train=0.998, test=0.392) total time= 11.2s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=10;, score=(train=0.999, test=0.212) total time= 13.2s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=10;, score=(train=0.999, test=0.465) total time= 13.3s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=10;, score=(train=1.000, test=0.102) total time= 12.8s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=10;, score=(train=0.999, test=0.546) total time= 13.3s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=10;, score=(train=0.998, test=0.385) total time= 12.7s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=11;, score=(train=1.000, test=0.191) total time= 15.2s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=11;, score=(train=1.000, test=0.481) total time= 15.5s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=11;, score=(train=1.000, test=0.104) total time= 14.9s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=11;, score=(train=1.000, test=0.539) total time= 16.4s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=11;, score=(train=1.000, test=0.368) total time= 15.1s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=12;, score=(train=1.000, test=0.197) total time= 17.6s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=12;, score=(train=1.000, test=0.470) total time= 17.8s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=12;, score=(train=1.000, test=0.096) total time= 16.8s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=12;, score=(train=1.000, test=0.540) total time= 16.9s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=12;, score=(train=1.000, test=0.347) total time= 16.6s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=13;, score=(train=1.000, test=0.199) total time= 19.7s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=13;, score=(train=1.000, test=0.475) total time= 19.9s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=13;, score=(train=1.000, test=0.087) total time= 19.5s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=13;, score=(train=1.000, test=0.520) total time= 20.1s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=13;, score=(train=1.000, test=0.336) total time= 19.0s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=14;, score=(train=1.000, test=0.188) total time= 21.8s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=14;, score=(train=1.000, test=0.441) total time= 22.3s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=14;, score=(train=1.000, test=0.078) total time= 21.7s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=14;, score=(train=1.000, test=0.512) total time= 22.2s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=14;, score=(train=1.000, test=0.322) total time= 20.8s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=15;, score=(train=1.000, test=0.157) total time= 24.2s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=15;, score=(train=1.000, test=0.452) total time= 25.7s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=15;, score=(train=1.000, test=0.076) total time= 23.9s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=15;, score=(train=1.000, test=0.529) total time= 24.4s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=0.5, clf__max_depth=15;, score=(train=1.000, test=0.298) total time= 23.9s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=5;, score=(train=0.990, test=0.236) total time= 5.1s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=5;, score=(train=0.989, test=0.473) total time= 5.1s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=5;, score=(train=0.994, test=0.146) total time= 5.1s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=5;, score=(train=0.986, test=0.575) total time= 5.1s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=5;, score=(train=0.987, test=0.421) total time= 5.4s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=6;, score=(train=0.996, test=0.243) total time= 6.2s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=6;, score=(train=0.995, test=0.489) total time= 6.3s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=6;, score=(train=0.999, test=0.116) total time= 6.2s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=6;, score=(train=0.995, test=0.565) total time= 6.3s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=6;, score=(train=0.994, test=0.401) total time= 6.3s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=7;, score=(train=0.999, test=0.218) total time= 7.5s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=7;, score=(train=0.998, test=0.472) total time= 7.7s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=7;, score=(train=1.000, test=0.109) total time= 7.6s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=7;, score=(train=0.998, test=0.562) total time= 7.6s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=7;, score=(train=0.996, test=0.393) total time= 7.4s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=8;, score=(train=1.000, test=0.224) total time= 8.9s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=8;, score=(train=0.999, test=0.462) total time= 9.0s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=8;, score=(train=1.000, test=0.112) total time= 8.8s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=8;, score=(train=0.999, test=0.516) total time= 9.0s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=8;, score=(train=0.999, test=0.409) total time= 9.0s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=9;, score=(train=1.000, test=0.198) total time= 10.7s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=9;, score=(train=1.000, test=0.473) total time= 10.6s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=9;, score=(train=1.000, test=0.109) total time= 10.4s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=9;, score=(train=1.000, test=0.531) total time= 10.6s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=9;, score=(train=1.000, test=0.369) total time= 10.4s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=10;, score=(train=1.000, test=0.227) total time= 12.4s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=10;, score=(train=1.000, test=0.448) total time= 12.6s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=10;, score=(train=1.000, test=0.114) total time= 12.3s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=10;, score=(train=1.000, test=0.542) total time= 12.2s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=10;, score=(train=1.000, test=0.377) total time= 12.3s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=11;, score=(train=1.000, test=0.209) total time= 14.3s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=11;, score=(train=1.000, test=0.455) total time= 14.5s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=11;, score=(train=1.000, test=0.105) total time= 13.8s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=11;, score=(train=1.000, test=0.547) total time= 13.9s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=11;, score=(train=1.000, test=0.351) total time= 13.7s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=12;, score=(train=1.000, test=0.183) total time= 16.1s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=12;, score=(train=1.000, test=0.458) total time= 16.2s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=12;, score=(train=1.000, test=0.106) total time= 15.8s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=12;, score=(train=1.000, test=0.531) total time= 15.8s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=12;, score=(train=1.000, test=0.354) total time= 15.4s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=13;, score=(train=1.000, test=0.189) total time= 18.1s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=13;, score=(train=1.000, test=0.468) total time= 18.2s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=13;, score=(train=1.000, test=0.094) total time= 18.2s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=13;, score=(train=1.000, test=0.511) total time= 18.0s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=13;, score=(train=1.000, test=0.321) total time= 17.4s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=14;, score=(train=1.000, test=0.189) total time= 20.6s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=14;, score=(train=1.000, test=0.453) total time= 21.3s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=14;, score=(train=1.000, test=0.088) total time= 19.9s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=14;, score=(train=1.000, test=0.524) total time= 20.2s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=14;, score=(train=1.000, test=0.329) total time= 19.6s [CV 1/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=15;, score=(train=1.000, test=0.170) total time= 23.1s [CV 2/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=15;, score=(train=1.000, test=0.456) total time= 23.8s [CV 3/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=15;, score=(train=1.000, test=0.091) total time= 22.6s [CV 4/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=15;, score=(train=1.000, test=0.507) total time= 22.2s [CV 5/5] END clf=GradientBoostingClassifier(), clf__learning_rate=1.0, clf__max_depth=15;, score=(train=1.000, test=0.317) total time= 21.5s [CV 1/5] END clf=MultinomialNB(), clf__alpha=1e-05;, score=(train=0.795, test=0.301) total time= 0.0s [CV 2/5] END clf=MultinomialNB(), clf__alpha=1e-05;, score=(train=0.794, test=0.461) total time= 0.0s [CV 3/5] END clf=MultinomialNB(), clf__alpha=1e-05;, score=(train=0.827, test=0.226) total time= 0.0s [CV 4/5] END clf=MultinomialNB(), clf__alpha=1e-05;, score=(train=0.769, test=0.591) total time= 0.0s [CV 5/5] END clf=MultinomialNB(), clf__alpha=1e-05;, score=(train=0.759, test=0.480) total time= 0.0s [CV 1/5] END clf=MultinomialNB(), clf__alpha=0.001;, score=(train=0.795, test=0.313) total time= 0.0s [CV 2/5] END clf=MultinomialNB(), clf__alpha=0.001;, score=(train=0.793, test=0.467) total time= 0.0s [CV 3/5] END clf=MultinomialNB(), clf__alpha=0.001;, score=(train=0.827, test=0.227) total time= 0.0s [CV 4/5] END clf=MultinomialNB(), clf__alpha=0.001;, score=(train=0.768, test=0.606) total time= 0.0s [CV 5/5] END clf=MultinomialNB(), clf__alpha=0.001;, score=(train=0.758, test=0.514) total time= 0.0s [CV 1/5] END clf=MultinomialNB(), clf__alpha=0.1;, score=(train=0.791, test=0.342) total time= 0.0s [CV 2/5] END clf=MultinomialNB(), clf__alpha=0.1;, score=(train=0.788, test=0.483) total time= 0.0s [CV 3/5] END clf=MultinomialNB(), clf__alpha=0.1;, score=(train=0.824, test=0.246) total time= 0.0s [CV 4/5] END clf=MultinomialNB(), clf__alpha=0.1;, score=(train=0.766, test=0.641) total time= 0.0s [CV 5/5] END clf=MultinomialNB(), clf__alpha=0.1;, score=(train=0.753, test=0.604) total time= 0.0s [CV 1/5] END clf=MultinomialNB(), clf__alpha=1.0;, score=(train=0.770, test=0.343) total time= 0.0s [CV 2/5] END clf=MultinomialNB(), clf__alpha=1.0;, score=(train=0.772, test=0.498) total time= 0.0s [CV 3/5] END clf=MultinomialNB(), clf__alpha=1.0;, score=(train=0.808, test=0.235) total time= 0.0s [CV 4/5] END clf=MultinomialNB(), clf__alpha=1.0;, score=(train=0.748, test=0.649) total time= 0.0s [CV 5/5] END clf=MultinomialNB(), clf__alpha=1.0;, score=(train=0.736, test=0.633) total time= 0.0s [CV 1/5] END clf=MultinomialNB(), clf__alpha=10.0;, score=(train=0.701, test=0.051) total time= 0.0s [CV 2/5] END clf=MultinomialNB(), clf__alpha=10.0;, score=(train=0.694, test=0.383) total time= 0.0s [CV 3/5] END clf=MultinomialNB(), clf__alpha=10.0;, score=(train=0.753, test=0.004) total time= 0.0s [CV 4/5] END clf=MultinomialNB(), clf__alpha=10.0;, score=(train=0.700, test=0.520) total time= 0.0s [CV 5/5] END clf=MultinomialNB(), clf__alpha=10.0;, score=(train=0.658, test=0.225) total time= 0.0s [CV 1/5] END clf=MultinomialNB(), clf__alpha=1000.0;, score=(train=0.628, test=0.000) total time= 0.0s [CV 2/5] END clf=MultinomialNB(), clf__alpha=1000.0;, score=(train=0.433, test=0.013) total time= 0.0s [CV 3/5] END clf=MultinomialNB(), clf__alpha=1000.0;, score=(train=0.666, test=0.000) total time= 0.0s [CV 4/5] END clf=MultinomialNB(), clf__alpha=1000.0;, score=(train=0.417, test=0.002) total time= 0.0s [CV 5/5] END clf=MultinomialNB(), clf__alpha=1000.0;, score=(train=0.512, test=0.000) total time= 0.0s [CV 1/5] END clf=MultinomialNB(), clf__alpha=100000.0;, score=(train=0.615, test=0.000) total time= 0.0s [CV 2/5] END clf=MultinomialNB(), clf__alpha=100000.0;, score=(train=0.417, test=0.000) total time= 0.0s [CV 3/5] END clf=MultinomialNB(), clf__alpha=100000.0;, score=(train=0.645, test=0.000) total time= 0.0s [CV 4/5] END clf=MultinomialNB(), clf__alpha=100000.0;, score=(train=0.417, test=0.000) total time= 0.0s [CV 5/5] END clf=MultinomialNB(), clf__alpha=100000.0;, score=(train=0.505, test=0.000) total time= 0.0s
GridSearchCV(cv=5, error_score='raise',
estimator=Pipeline(steps=[('clf', None)]),
param_grid=[{'clf': [LogisticRegression()],
'clf__C': [1e-05, 0.001, 0.1, 10.0, 1000.0, 100000.0],
'clf__penalty': ['l1', 'l2'],
'clf__solver': ['liblinear']},
{'clf': [LinearSVC()],
'clf__C': [1e-05, 0.001, 0.1, 10.0, 1000.0, 100000.0],
'clf__dual': [False], 'clf__penalty': ['l1', 'l2']},
{'clf': [...
'clf__n_neighbors': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]},
{'clf': [RandomForestClassifier()],
'clf__max_depth': [5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15]},
{'clf': [GradientBoostingClassifier()],
'clf__learning_rate': [0.1, 0.5, 1.0],
'clf__max_depth': [5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15]},
{'clf': [MultinomialNB()],
'clf__alpha': [1e-05, 0.001, 0.1, 1.0, 10.0, 1000.0,
100000.0]}],
return_train_score=True, scoring='accuracy', verbose=3)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
GridSearchCV(cv=5, error_score='raise',
estimator=Pipeline(steps=[('clf', None)]),
param_grid=[{'clf': [LogisticRegression()],
'clf__C': [1e-05, 0.001, 0.1, 10.0, 1000.0, 100000.0],
'clf__penalty': ['l1', 'l2'],
'clf__solver': ['liblinear']},
{'clf': [LinearSVC()],
'clf__C': [1e-05, 0.001, 0.1, 10.0, 1000.0, 100000.0],
'clf__dual': [False], 'clf__penalty': ['l1', 'l2']},
{'clf': [...
'clf__n_neighbors': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]},
{'clf': [RandomForestClassifier()],
'clf__max_depth': [5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15]},
{'clf': [GradientBoostingClassifier()],
'clf__learning_rate': [0.1, 0.5, 1.0],
'clf__max_depth': [5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15]},
{'clf': [MultinomialNB()],
'clf__alpha': [1e-05, 0.001, 0.1, 1.0, 10.0, 1000.0,
100000.0]}],
return_train_score=True, scoring='accuracy', verbose=3)Pipeline(steps=[('clf', None)])None
Best Scores per Model
grid_df = pd.DataFrame(grid_search.cv_results_)
grid_df['param_clf'] = grid_df['param_clf'].astype(str)
per_model = grid_df.loc[grid_df.groupby('param_clf')['rank_test_score'].idxmin()]
per_model[
['param_clf', 'rank_test_score', 'mean_test_score', 'mean_train_score',
'mean_fit_time', 'mean_score_time']
].sort_values(by='rank_test_score')
| param_clf | rank_test_score | mean_test_score | mean_train_score | mean_fit_time | mean_score_time | |
|---|---|---|---|---|---|---|
| 81 | MultinomialNB() | 1 | 0.471457 | 0.766831 | 0.002994 | 0.001374 |
| 7 | LogisticRegression() | 4 | 0.423049 | 0.929494 | 0.395127 | 0.001513 |
| 19 | LinearSVC() | 5 | 0.420681 | 0.962382 | 2.630117 | 0.001585 |
| 67 | GradientBoostingClassifier() | 18 | 0.370294 | 0.989083 | 5.158388 | 0.009540 |
| 24 | KNeighborsClassifier() | 54 | 0.302572 | 1.000000 | 0.003242 | 0.250982 |
| 44 | RandomForestClassifier() | 68 | 0.144859 | 0.778975 | 0.606247 | 0.035438 |
Best Model to Use
print(f"The best model is: {grid_search.best_params_}")
print(f"with an accuracy score of: {grid_search.best_score_}")
The best model is: {'clf': MultinomialNB(), 'clf__alpha': 1.0}
with an accuracy score of: 0.47145719248903967
Train and Test: Multinomial Naive Bayes
The resulting best model from GridSearch was the Multinomial Naive Bayes model with alpha=1. This was used to train and test the dataset.
Fit
reg = MultinomialNB(alpha=1)
reg.fit(X_resampled_countvec, y_resampled)
MultinomialNB(alpha=1)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
MultinomialNB(alpha=1)
Score
reg_train_score = reg.score(X_resampled_countvec, y_resampled)
reg_test_score = reg.score(X_test_countvec, y_test)
print(f'Train Score: {reg_train_score}')
print(f'Test Score: {reg_test_score}')
Train Score: 0.738901018922853 Test Score: 0.6992713623316406
Top 10 Features
log_probabilities = reg.feature_log_prob_
n_top_features = 10
# Concatenate feature names with corresponding classes
all_features = np.concatenate(
[feature_names[np.argsort(log_probabilities[i])[::-1][:n_top_features]] \
for i in range(log_probabilities.shape[0])])
all_labels = np.concatenate([
['Negative'] * n_top_features,
['Neutral'] * n_top_features,
['Positive'] * n_top_features
])
# Get the unique top 10 features
unique_top_features, indices = np.unique(all_features, return_index=True)
top_10_features = unique_top_features[:n_top_features]
top_10_labels = all_labels[indices][:n_top_features]
reg_top_features = pd.DataFrame({
'Top Feature': top_10_features,
'Sentiment': top_10_labels
})
reg_top_features
| Top Feature | Sentiment | |
|---|---|---|
| 0 | color | Neutral |
| 1 | dress | Negative |
| 2 | fabric | Negative |
| 3 | fit | Negative |
| 4 | great | Positive |
| 5 | just | Negative |
| 6 | like | Negative |
| 7 | look | Negative |
| 8 | love | Negative |
| 9 | size | Negative |
Train and Test: TextBlob Naive Bayes
From the TextBlob library the NaiveBayes Classifier is called to train, and then to test the dataset. Because TextBlob only looks for a list of tuples of the text and the target variable, the only data passed to the classifier is the resampled dataset (eg. "Absolutely wonderful - silky and sexy and comfortable" - "positive"), and not the vectorized dataset.
Fit
train_df = pd.concat([X_resampled, y_resampled], axis=1)
test_df = pd.concat([X_test, y_test], axis=1)
# the datasets are turned into a list of tuples
train = [(row['Review Text'], row['Sentiment']) \
for index, row in train_df.iterrows()]
test = [(row['Review Text'], row['Sentiment']) \
for index, row in test_df.iterrows()]
# call the classifier
tb = NaiveBayesClassifier(train)
Score
tb_train_score = tb.accuracy(train)
tb_test_score = tb.accuracy(test)
print(f'Train Score: {tb_train_score}')
print(f'Test Score: {tb_test_score}')
Train Score: 0.8089519650655022 Test Score: 0.6637226760874365
Top 10 Features
tb.show_informative_features(10)
Most Informative Features
contains(awful) = True 1 : 3 = 31.0 : 1.0
contains(horrible) = True 1 : 3 = 17.7 : 1.0
contains(shame) = True 1 : 3 = 17.0 : 1.0
contains(flimsy) = True 1 : 3 = 16.3 : 1.0
contains(highly) = True 3 : 1 = 15.8 : 1.0
contains(occasion) = True 3 : 1 = 15.7 : 1.0
contains(mess) = True 1 : 3 = 15.0 : 1.0
contains(unflattering) = True 1 : 3 = 14.6 : 1.0
contains(justice) = True 3 : 1 = 14.3 : 1.0
contains(literally) = True 1 : 3 = 14.3 : 1.0
Results and Discussion
To measure the performance of each of the models, and to gain an apples-to-apples comparison, the accuracy score of each model is compared. We also output the top 10 features (words) from each model for comparison.
Model Scores Comparison
Train and Test Scores for Traditional ML and TextBlob Classifier
data = {
'Type': ['Traditional ML', 'TextBlob'],
'Specific Model': ['Multinomial Naive Bayes', 'Naive Bayes Classifier'],
'Train Score': [reg_train_score, tb_train_score],
'Test Score': [reg_test_score, tb_test_score]
}
# Creating a DataFrame
df_scores = pd.DataFrame(data)
df_scores
| Type | Specific Model | Train Score | Test Score | |
|---|---|---|---|---|
| 0 | Traditional ML | Multinomial Naive Bayes | 0.738901 | 0.699271 |
| 1 | TextBlob | Naive Bayes Classifier | 0.808952 | 0.663723 |
Top 10 Features Comparison
Top Features from Traditional ML - Multinomial Naive Bayes
reg_top_features
| Top Feature | Sentiment | |
|---|---|---|
| 0 | color | Neutral |
| 1 | dress | Negative |
| 2 | fabric | Negative |
| 3 | fit | Negative |
| 4 | great | Positive |
| 5 | just | Negative |
| 6 | like | Negative |
| 7 | look | Negative |
| 8 | love | Negative |
| 9 | size | Negative |
Top Features from TextBlob - Naive Bayes Classifier
tb.show_informative_features(10)
Most Informative Features
contains(awful) = True 1 : 3 = 31.0 : 1.0
contains(horrible) = True 1 : 3 = 17.7 : 1.0
contains(shame) = True 1 : 3 = 17.0 : 1.0
contains(flimsy) = True 1 : 3 = 16.3 : 1.0
contains(highly) = True 3 : 1 = 15.8 : 1.0
contains(occasion) = True 3 : 1 = 15.7 : 1.0
contains(mess) = True 1 : 3 = 15.0 : 1.0
contains(unflattering) = True 1 : 3 = 14.6 : 1.0
contains(justice) = True 3 : 1 = 14.3 : 1.0
contains(literally) = True 1 : 3 = 14.3 : 1.0
Discussion
Recap on the Process
With the traditional Machine Learning method and with TextBlob, the dataset was treated the same. In preprocessing, the rows with null Review Text were removed (1), the data was split into 80% trainval and 20% test sets (2), and the training data was resampled using Random Undersampling (3).
For the Traditional ML methodology, the reviews text were lemmatized and vectorized using Spacy's lemmatization feature and Count Vectorizer respectively. Different classification models were used in GridSearch to find the best model, resulting to Multinomial Naive Bayes being the best model. The Multinomial Naive Bayes was used to train and test the dataset.
On the other hand, TextBlob offers an easy call to their classifiers, which allows us to train and test the model to our own dataset. The Naive Bayes classifier from the library was used to train and test the dataset.
Results Comparison and Pros and Cons
TextBlob Classifier is easily accessible and user-friendly, requiring no parameter tuning for quick deployment. However, this simplicity comes at the cost of limited visibility into tuning parameters and no direct access to individual top features when called.
In contrast, Traditional ML involves a more intricate process, with multiple steps required before identifying and utilizing the best model.
In both instances, the Naive Bayes model served as the basis for comparison. Renowned for its efficacy in text classification, Naive Bayes excels in multi-classification tasks, often outperforming alternative models (Ray, 2023).
Utilizing Multinomial Naive Bayes from SKLearn, Traditional ML achieved a superior test accuracy compared to TextBlob's Naive Bayes Classifier. This disparity may stem from custom preprocessing steps employed independently, diverging from the constraints of the TextBlob library. Unlike TextBlob, the library lacks customization options and parameter hyper-tuning capabilities.
Upon examining the top features of both methods, TextBlob predominantly yields adjectives. While these words distinctly convey sentiment, such as 'flimsy,' 'shame,' and 'unflattering' signaling negativity, they offer limited additional insights to stakeholders. The challenge lies in comprehending the underlying reasons behind the sentiment, as adjectives alone may not provide sufficient context or specific actionable points for improvement.
Conversely, Traditional ML's top words encompass both adjectives and nouns. Notably, negative reviews feature terms like 'dress,' 'fit,' and 'size.' This signals a need for alterations in garment fit and size, especially for dresses. Surprisingly, positive terms like 'like' and 'love' emerge as top features for negative reviews, warranting deeper investigation into the context and nuances of such occurrences.
Conclusion and Recommendations
Conclusion
Although leveraging libraries like TextBlob provides convenient access to text classification methods, it comes at the cost of reduced visibility and customization compared to a bespoke model.
Both models exhibit high accuracy and surpass the Proportion Chance Criterion, with Multinomial Naive Bayes achieving slightly superior accuracy compared to TextBlob.
TextBlob serves as an excellent choice for rapid implementation of text classification tasks, offering simplicity and ease of use. On the other hand, a custom model is ideal for situations demanding meticulous customization and seamless integration into a workflow, particularly when specific preprocessing of the data is required.
Recommendations
For individuals with a keen interest in Natural Language Processing (NLP), we highly recommend exploring and experimenting with the diverse functionalities offered by TextBlob. The versatility of TextBlob makes it an excellent tool for tasks such as sentiment analysis, part-of-speech tagging, and more.
Furthermore, we suggest considering the creation of a custom text classification model for those seeking greater flexibility and control, particularly in scenarios where specific requirements need to be addressed on a case-by-case basis. Custom models allow for the implementation of various preprocessing settings and methods, providing an opportunity for optimization based on specific needs. We encourage individuals to explore and experiment with different preprocessing approaches, as this can significantly impact the performance and effectiveness of a custom NLP model.
References
Loria, S. (2013). TextBlob Documentation. TextBlob. Retrieved December 9, 2023 from https://textblob.readthedocs.io/en/dev/index.html
Nicapotato. (2017). Women's E-Commerce Clothing Reviews. Retrieved December 9, 2023 from https://www.kaggle.com/datasets/nicapotato/womens-ecommerce-clothing-reviews
Ray, S. (2023, December 1). Naive Bayes Classifier Explained: Applications and Practice Problems of Naive Bayes Classifier. Analytics Vidhya. Retrieved December 9, 2023 from https://www.analyticsvidhya.com/blog/2017/09/naive-bayes-explained/
Note: ChatGPT was used to generate code, and paraphrase the thoughts of the author.